Продолжаем наши приключения с оптимизацией сборки Java Spring приложений и собственно и прикинем, что мы можем сделать и даже сделаем.
Есть ли у вас план, мистер Фикс? Есть ли у меня план? Есть ли у меня план? Да у меня целых три плана!
Первое, и самое простое, что приходит в голову, это поменять политику загрузки образов с постоянно скачивать, на скипать если такой образ уже есть и для этого в файле /etc/gitlab-runner/config.toml добавляем записи в раздел [runners.docker].
pull_policy = ["if-not-present"]
allowed_pull_policies = ["always", "if-not-present"]Естественно, что сервис надо будет перезапустить, а секция целиком будет примерно такая.
[runners.docker]
tls_verify = false
image = "docker:20.10.5"
pull_policy = ["if-not-present"]
allowed_pull_policies = ["always", "if-not-present"]
privileged = false
disable_entrypoint_overwrite = false
oom_kill_disable = false
disable_cache = false
volumes = ["/var/run/docker.sock:/var/run/docker.sock", "/cache"]
shm_size = 0Супер прироста от этого не будет, но с чего-то же надо начинать.
Следующим этапом клонируем число сборщиков в зависимости от размера команды разработки или если вы используете кубер и я тут писал как (Запуск gitlab-runner в Kubernetes), то там еще проще можно сделать и наплодить их хоть сто по запросу, но есть нюанс, что вы устроите хаос в админке, так-как они из админки то они не удаляются так-же по запросу 🙂 Так мы получаем горизонтальное масштабирование.
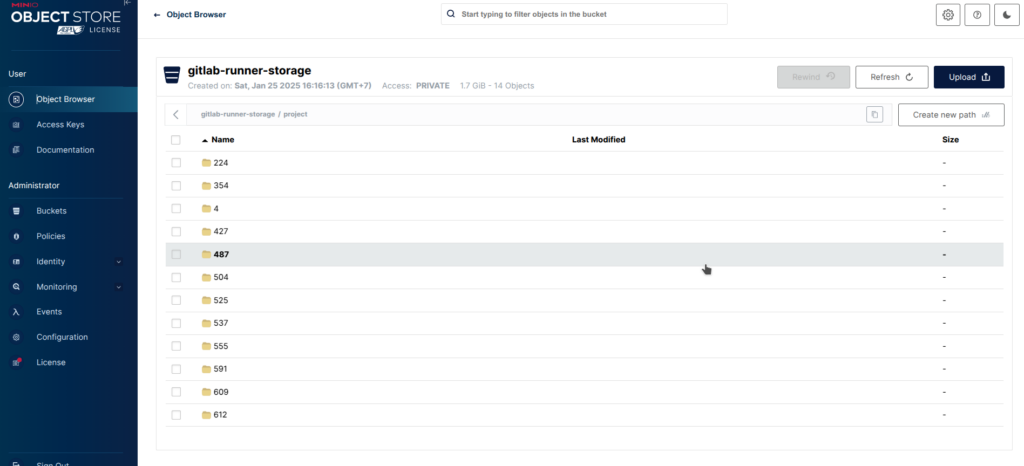
Далее мы получаем прикол с кэшем скачанных файлов и на каждом ранере он будет свой и если их у вас как и у меня их больше десяти, то это становится проблемкой, так-как выбирается первый доступный. Проблемка решается довольно легко и нам надо только поднять S3 хранилку (тут я написал как просто это сделать Установка и запуск MinIo), создаем бакет, создаем пользователя, накручиваем ему права и получаем токен и ключик.
Теперь так-же прописываем в секцию [runners.cache] что-то вот такое.
[runners.cache]
MaxUploadedArchiveSize = 0
Type = "s3"
Shared = true
[runners.cache.s3]
ServerAddress = "s3-01.xxxxxxxx:9000"
AccessKey = "xxxxxxxxxxxxxxxx"
SecretKey = "xxxxxxxxxxxxxxxxxxxxx"
BucketName = "gitlab-runner-storage"
BucketLocation = "ru-nsk-1"
Insecure = trueЕсли вы не вытаскиваете S3 в дикий интернет, то обратите внимание на параметр Insecure = true. По умолчанию подключение к бакету происходит по https.
Получается вот такая красота.
Собсно, на этом все и теперь больше и покрутить то вроде нечего. Если, кто еще знает чего покрутить, то пишите.
P.S. Ну еще пример как для спринга кэш описать для докер-билдера.
Build CHATRA-STATISTICS:
image:
name: maven:3.8.1-openjdk-17
stage: Build APPS
tags:
- image-builder
cache:
paths:
- .m2/repository
variables:
MAVEN_OPTS: "-Dmaven.repo.local=$CI_PROJECT_DIR/.m2/repository"
script:
- echo "CHATRA-STATISTICS"
- echo $CI_SMS_MAVEN_KEYS > ./maven_settings.xml
- mvn -DskipTests -s ./maven_settings.xml -f ./pom.xml clean install
artifacts:
paths:
- ./target/*.jar
expire_in: 1 day